
ABSTRACT
A comparative evaluation of several popular WWW search engines (AltaVista, Excite, InfoSeek, and Lycos) is reported. Five faculty members generated a list of four to six keywords for a focused research topic. After running the keywords through the search engines, subjects evaluated the first ten WWW sites found by each search engine and rated their quality. Signal Detection analysis yields two scores for each search engine. One score (d') measures the sensitivity of the search engine in finding useful information. The other score (beta) measures how conservative or liberal the search engine is in determining which sites to include in its output. The results highlight the overall poor performance of the current technology and provides an objective research methodology for analyzing future developments.
Keywords
Search Engines, Signal Detection, Resource Discovery
INTRODUCTION
Global communication is becoming increasingly important and the amount of available information goes along with the increasing communications infrastructure. The vast capacity of electronic storage systems theoretically enables us to keep an enormous amount of information. The World-Wide-Web technology makes this information available to the entire communication society. Concomitant with the information explosion is the difficulty in locating relevant information. Search engines are among the most popular tools for resource discovery on the WWW. A plethora or search engines have become available recently. Reviews of search engines have appeared in a published (Tennant, 1996) as well as online (Liu, 1996) format. These reviews generally mention some of the technical aspects of the search engines such as the size of the database and the authors experience and personal preference.
Obviously all search engines follow different algorithms to index information on the web and to output results to a user's query. In order to be effective on the web, it is important to utilize the search engine most suited to your subject domain. However, many reviews do not include a ranking, which could help to make a decision for one specific search engine. Some of the existing rankings have no scientific base and are represented as a number of stars that a search engine receives (Arents, 1996). An attempt to give some performance comparison has been made by Winship (1995). Table 4 of his paper lists three different search queries and the number of results created by six databases. Winship points out that the number of results does not permit any conclusions about the usefulness of the various search engines because duplication of links and irrelevant links distort that measurement. Leighton (1995) considered those problems and counted only the number of relevant links, ignoring the duplicates. However, he created the queries himself, resulting in experimenter bias.
With the advent of huge search engines like AltaVista, containing up to 30 million homepages, measuring the number of hits is no longer an effective measure. The question of the quality of the hits rather than their quantity is becoming more important. One approach to this information labyrinth is to use a WWW directory that has fewer pages that have been entered into the database upon passing some kind of quality test. One problem with this approach is that the directory administration and the user of the directory might have different standards concerning quality. Additionally the user might just look for some personal information that would not be contained in such an index. This leaves the user to deal with a comprehensive search engine.
The goal of this research is to demonstrate a methodology that can be used to compare search engines and future intelligent resource discovery objectively. In order for such a performance measure to be valid, it needs some form of evaluating the quality of the results created by the search engine.
METHOD
Five subjects, all faculty at Lewis and Clark College, were asked to think of some specific information which they would like to find on the WWW and for which they had not conducted searches yet themselves. In a short paragraph, they described the information they were looking for. Additionally they formulated 4 - 6 keywords for a search query. The words were listed in the order of importance/relevance to the topic. The researchers then used these keywords to run searches on several search engines (AltaVista, Lycos, Infoseek and Excite). Phrases for concepts such as "color measurement" were used if the search engines permitted so (e.g. AltaVista and Infoseek). The first ten hits of all four search engines were combined in one single document. If a search engine located less than ten results, these results were added to the document and the search was run again with the least important keyword removed. From the new results only the first few hits were used so that their number together with the previous hits added up to ten. They were then reviewed and scored by the subjects according to usefulness and relevance to their search. First, the subjects decided if the hit was relevant to their search. If the hit was relevant, the subjects scored its usefulness on a scale from one to seven with seven being the most useful.
RESULTS
The simplest reporting of the results would be to count the number of relevant links returned by each search engine. A total of 54 relevant links were found of the total of 200 links generated by all five queries. Lycos retrieved the largest number of relevant links with 19, Excite found 14, Infoseek returned 12, and AltaVista trailed with a total of 9 relevant links found. The problem with reporting only the number of relevant links is that it only uses a small amount of the data and ignores the broader context of the information search. The method of Signal Detection Analysis allows a more detailed look at the performance of the search engines by incorporating more information into an integrated framework.
The first step in the Signal Detection Analysis (SDA) is to assign the links returned by each of the four search engines into one of four categories. Figure 1 lists and describes the categories. This categorization is based on the subject's yes/no judgment of each link's relevance. This procedure was done separately for each search engine collapsed across the five queries.
Figure 1. SDA Categories for Search Engine Links
The next step is to determine the hit rate and false alarm rate
for each search engine. The hit rate is defined as the proportion
of "good links" (Hits) found by a search engine relative
to the total number of "good links" found by all four
search engines (Hits + Misses). Similarly, the false alarm rate
is the proportion of "bad links" (False alarms) found
by a search engine relative to the total number of "bad links"
found by all four search engines (False Alarms + Correct Rejections).
Ideally, a search engine should produce a high hit rate and a
low false alarm rate. The obtained rates are reported in figure
2.
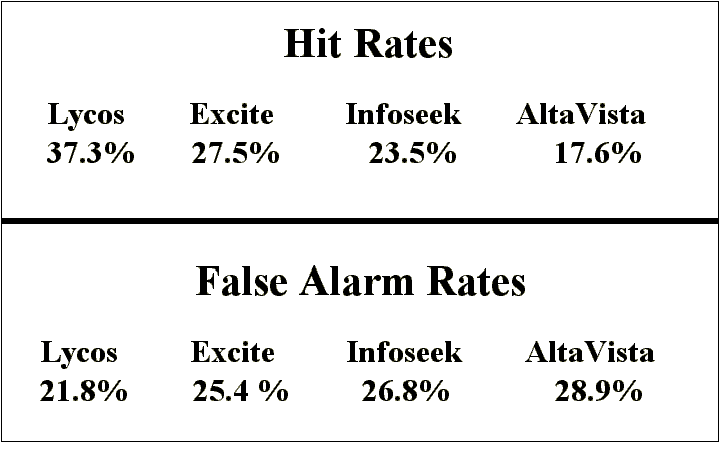
Figure 2. Hit and False Alarm Rates Combined for all Five Search
Queries
Using standard formulas and table look-ups based on the hit and
false alarm rates (Swets, 1964) the Signal Detection Analysis
yields two scores for each search engine. One score (d') measures
the sensitivity of the search engine in finding useful information.
The larger the d', the better. A typical range of d' scores is
from 0 to 2. A score of 0 means that the search engine is unable
to discriminate between good and bad links. The other score (beta)
measures decision bias, how conservative or liberal the search
engine is in reporting sites. The larger the beta value, the more
conservative the search engine is in reporting sites. In this
context, conservative behavior is missing some hits in an effort
to keep the number of false alarms to a minimum, while liberal
means accepting a higher false alarm rate in exchange for reporting
the highest percentage of hits. In theory, these measures are
separable. The obtained scores are presented in figure 3.
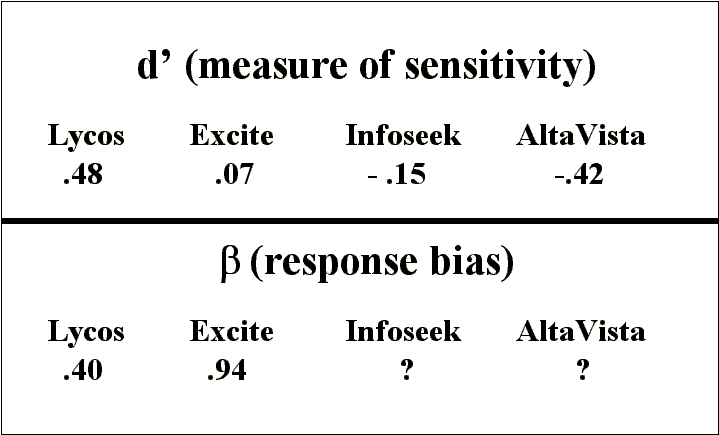
Figure 3. SDA Scores for Each Search Engine Combined for all Five
Search Queries
Of the four search engines, only Lycos displayed a respectable
d' score. The negative values for Infoseek and AltaVista are especially
troubling. They suggest that the performance of the search engines
in this experiment is too poor to fit the standard assumptions
of SDA. One central assumption is that the distribution of sites
containing relevant links (Hits + Misses) is more likely to be
indexed by the search mechanism than those sites containing irrelevant
links (False Alarms + Correct Rejections). This violation of assumptions
also complicates the interpretation of the beta score. Lycos has
a fairly liberal criterion level compared to Excite. However,
the calculations for beta are not interpretable when the d' is
negative. Thus, we cannot determine the response bias of Infoseek
or AltaVista.
An additional interesting finding is that there is almost no overlap
among the links retrieved by the four search engines. Out of a
total of 200 links, only five were found by two of the search
engines. This is an surprising result, considering the detail
of the queries.
DISCUSSION
The clearest result is that the performance of the search engines is far from ideal. None of the search engines approached an acceptable level of performance for these highly focused, academically oriented queries. The successful application of Signal Detection Analysis requires improvement of the searching technology or a change in the focus of the study.
Future research will apply SDA to measure the effectiveness of different search strategies within a single Search Engine. For example, contrasting "or" and "and" boolean operators in the construction of search queries. Other possibilities include comparing the Concept vs. Keyword search used by Excite, and varying the number of keywords used in a search query. This research will contribute an empirical test of the guidelines provided by many search engines for constructing a successful search.
This study only utilized the first ten sites returned from each
search since it was assumed that users are unlikely to search
beyond the first screen of data. A follow-up study will test this
assumption empirically. Using an eye-tracking computer, we will
observe how many sites users actually look at when presented with
the results of a search query, as well as recording where they
are looking on the screen.
The contribution of this paper is in identifying an objective
method of evaluating the effectiveness of extant and future technologies
for resource discovery. The purpose of this research is not to
show which of the selected search engines is superior. By the
time this paper is presented there may be superior technology
available. With improved search technology, Signal Detection Analysis
has the potential to provide useful information which goes beyond
ad hoc reporting of personal preferences, simple counts of links
found, or the number of stars or apples which a reviewer subjectively
assigns a service.
REFERENCES
Arents, Hans C. (1996). Search Engines. K.U.Leuven.
URL: http://www.mtm.kuleuven.ac.be/Services/fsearch.html
First created: Aug 29, 1995; Last modified: Apr 21, 1996.
Leighton Vernon H. (1995). Performance of Four World Wide Web
(WWW) Index Services: Infoseek, Lycos, Webcrawler and WWWWorm.
URL: http://www.winona.msus.edu/services-f/library-f/webind.htm
Liu, Jian (1996). Understanding WWW Search Tools. Reference Department,
IUB Libraries.
URL: http://www.indiana.edu/~librcsd/search
First Draft: September 1995, First Update: February 1996.
Swets, J.A., (Ed.) Signal Detection and Recognition by Human Observers. New York: Wiley (1962)
Tennant, Roy (1996). The Best Tools for Searching the Internet. Syllabus, February 1996, pp. 36 -38.
Winship, Ian R. (1995). World Wide Web searching tools - an evaluation.
Information Services Department, University of Northumbria at
Newcastle, UK.
URL: http://www.bubl.bath.ac.uk/BUBL/IWinship.html